GPT-5は期待外れ?むしろAIの飛躍的向上への予兆?


GPT-5の性能は期待外れだった?
OpenAIはGPT-5を2025年8月8日にリリースした。GPT-4リリースから2年強経っていたこともあり、その性能とそれがもたらす新たな用途に世間の期待が高まっている中での発表だった。
AGI pilledな言説(人間にできる認知タスクのほとんどをコスパよくこなせるAIシステム=AGIが数年以内に実現し、世界を変えるというナラティブ)も世間を覆い、「Situational Awareness」や「AI 2027」といったエッセイやレポートがその期待を補強していた。
しかし、その矢先にリリースされたGPT-5は、2024年12月に発表された「OpenAI o3」(以下、o3)から飛躍的に性能が向上したとは言い難いものだった。
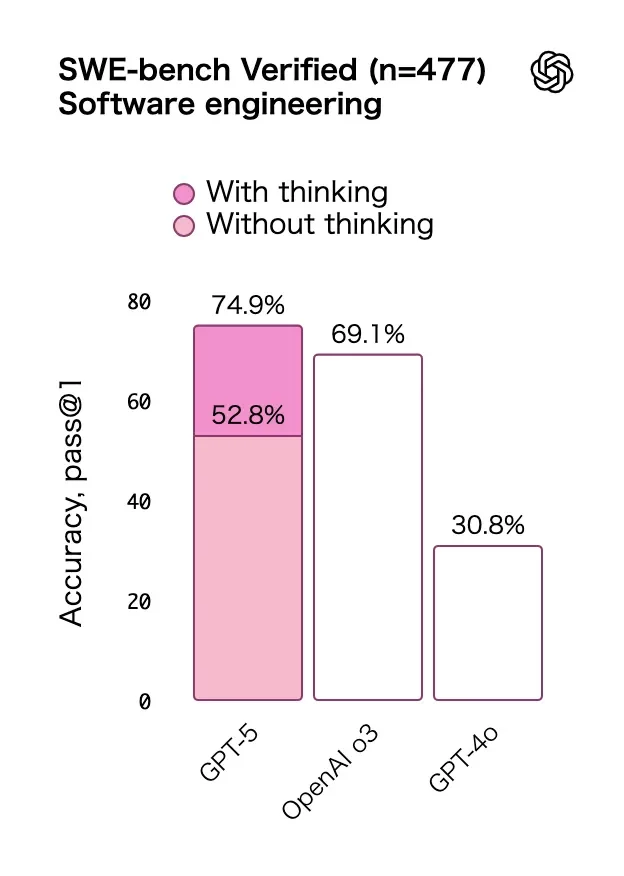
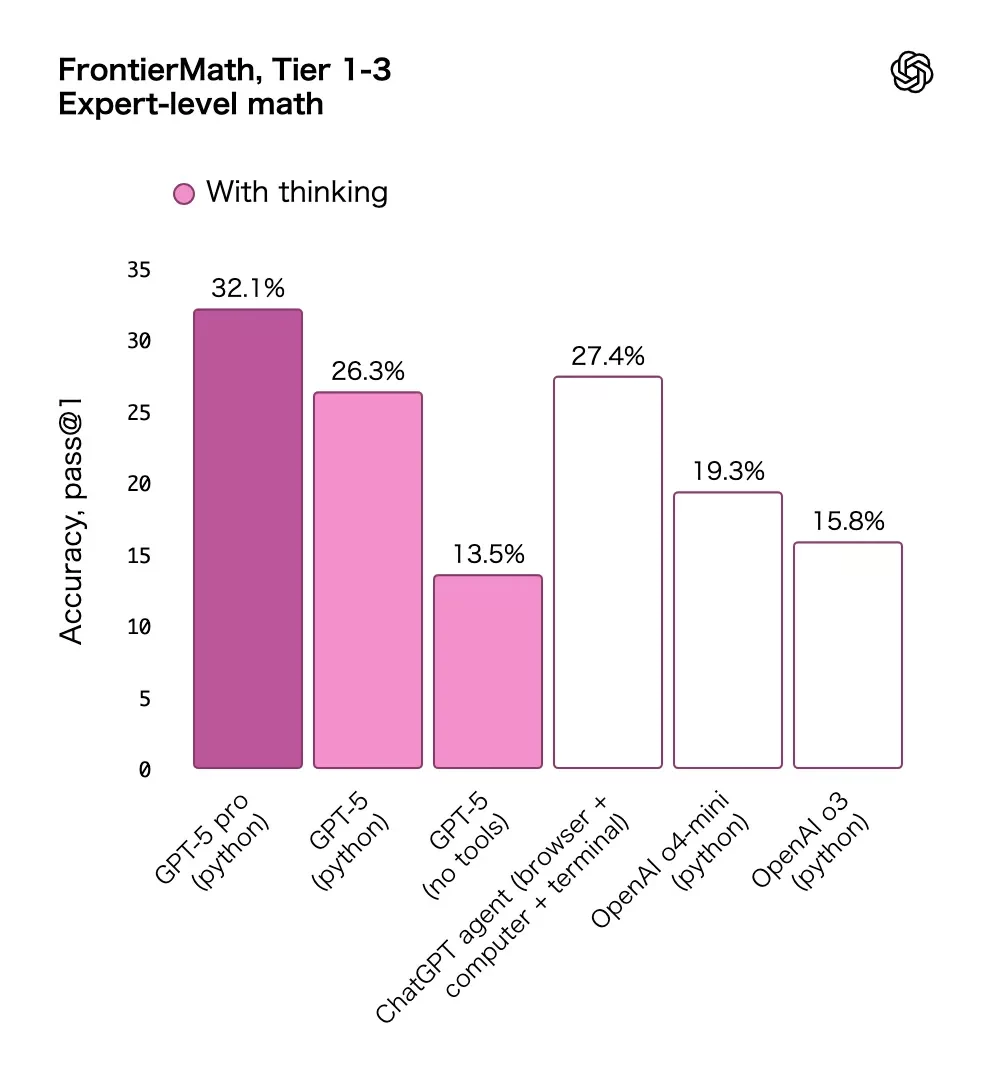
2つのベンチマークの結果。
図:「GPT-5 が登場」から。
ソフトウェアエンジニアリングに関するベンチマークのSWE-bench Verifiedでは69.1%から74.9%、数学者にとっても難しい問題を集めたFrontierMathではo4-mini(python)からGPT-5(python)で19.3%から26.3%だ。確かに進歩はしているが、大きな飛躍とは言い難い。
また、エージェント能力、自律性のベンチマーク面においてもある意味期待はずれなものだった。
「AI 2027」は、2027年末までにAGIが開発される可能性があるとした上で、2025年に「Agent-0」と呼ばれるAIが出現し、METRのソフトウェアエンジニアリングに関する自律性のベンチマークで、およそ「「人間がやると1時間かかるタスクを、80%の確率で自律的にこなせる」レベルになると予想していた。
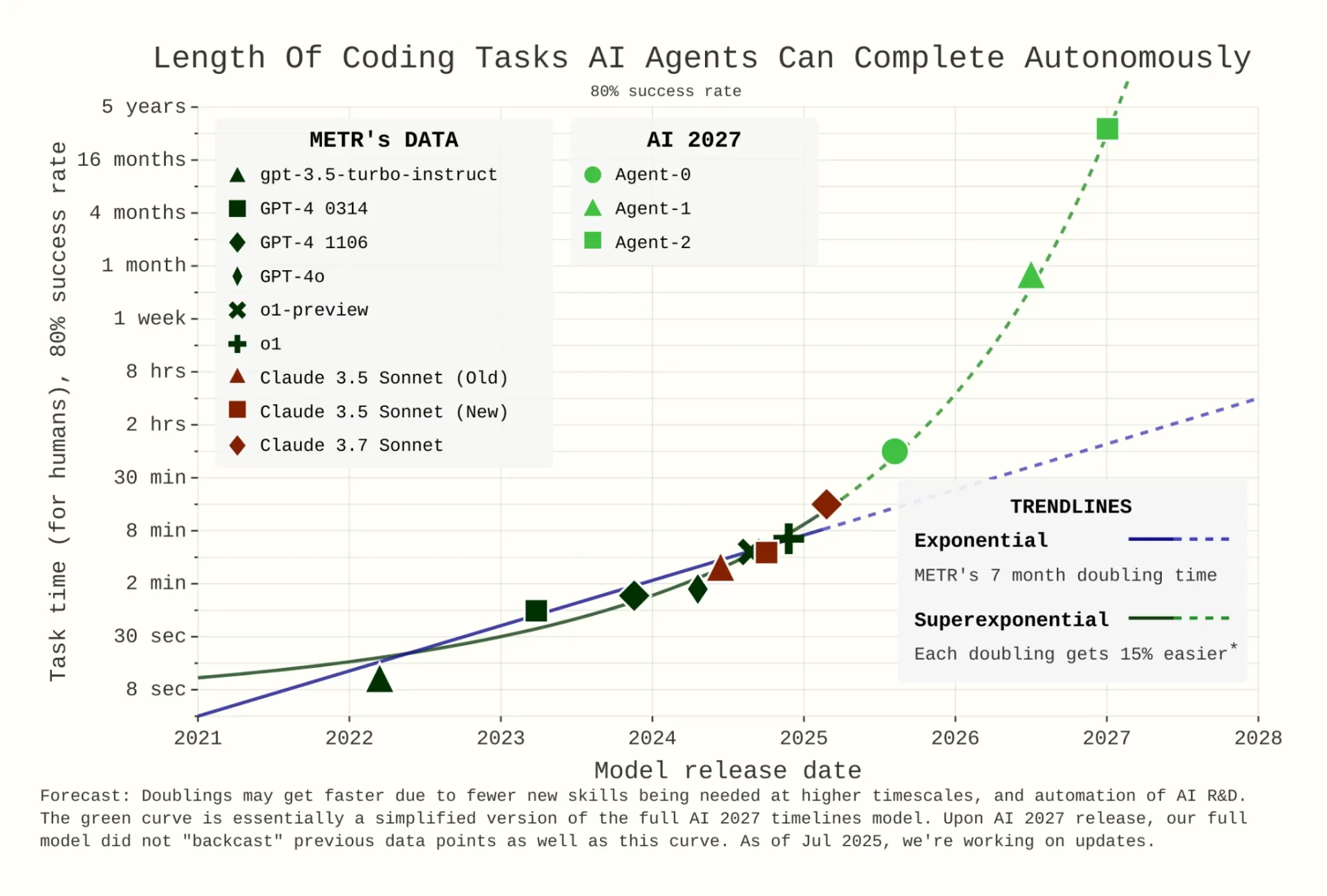
AIエージェントが自律的に完了できるコーディングタスクの長さ
図:「AI 2027」の脚注「Why we forecast a superhuman coder in early 2027」から
しかし現実にはGPT-5は人間なら26分でできるタスクを自律的に80%の確率で完了するという結果になった。AI2027の予想の1時間よりも短いタスクしか現状行えていない。
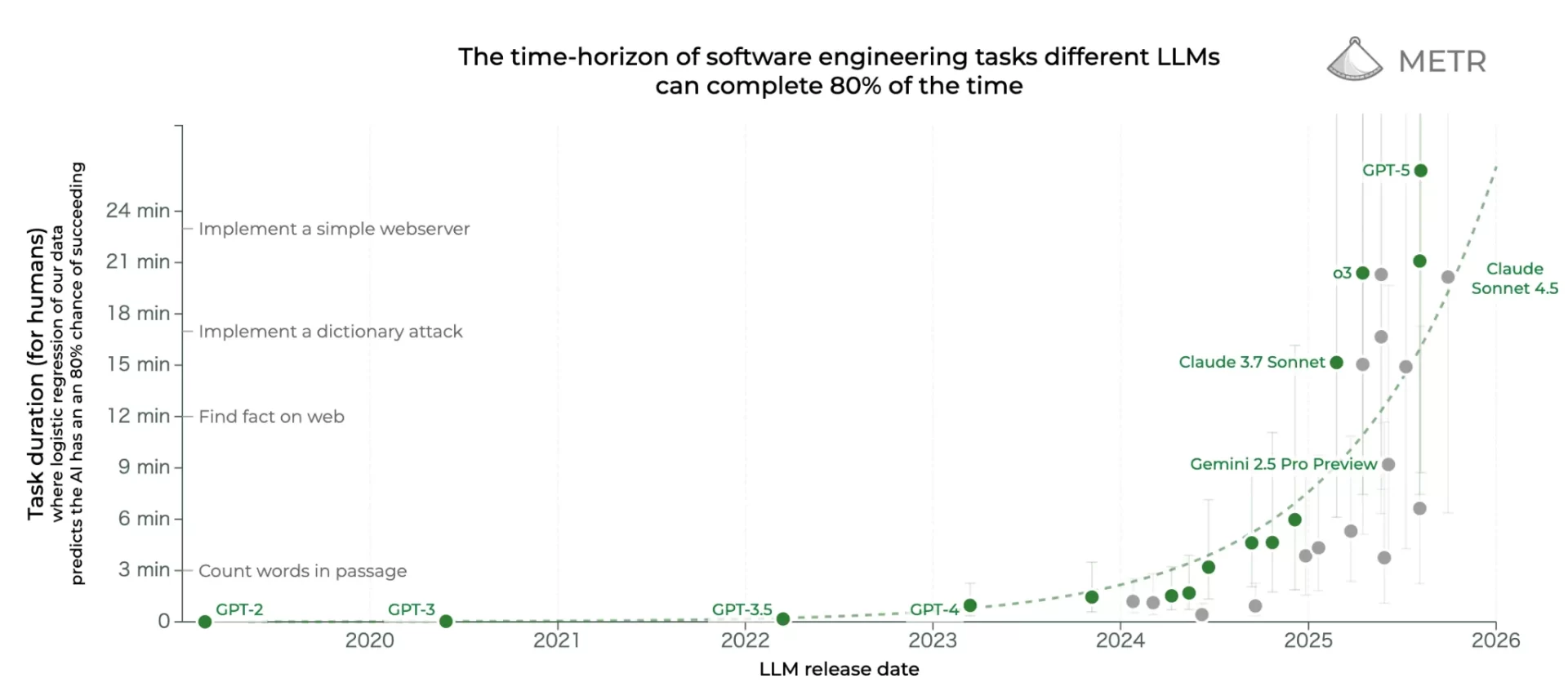
LLMが80%の確立で完了できるソフトウェア開発タスクの所要時間
図:「Measuring AI Ability to Complete Long Tasks」から
確かにGPT-5はハルシネーションが減少していたり、コストが安くなっている。ルーティング機能がついて週間アクティブユーザー7億人が推論モデルを使用できるようになったインパクトは大きい。GPT-5が目標にしているのは純粋な性能向上ではなく、多くの人にAIの価値を感じさせ、ターゲットを巨大な消費者市場に広げることだというSemianalysisの考察もある。
一方で純粋な性能向上という面ではインパクトを感じづらい人も多かったのではないだろうか。
ここで疑問が湧いてくる。GPT-5のリリースはOpenAIが基本路線とする開発時の学習計算量を増やすことによってAI性能を向上させるという傾向から外れたイベントだったのだろうか?
GPT-5はGPT-4からほとんど開発時の計算量が増えていない
AIトレンドを緻密に分析しているEpochAIは、GPT-5の開発時の学習計算量はGPT-4からほとんど増えておらず、GPT4.5より少ない学習計算量で訓練されたと指摘している。
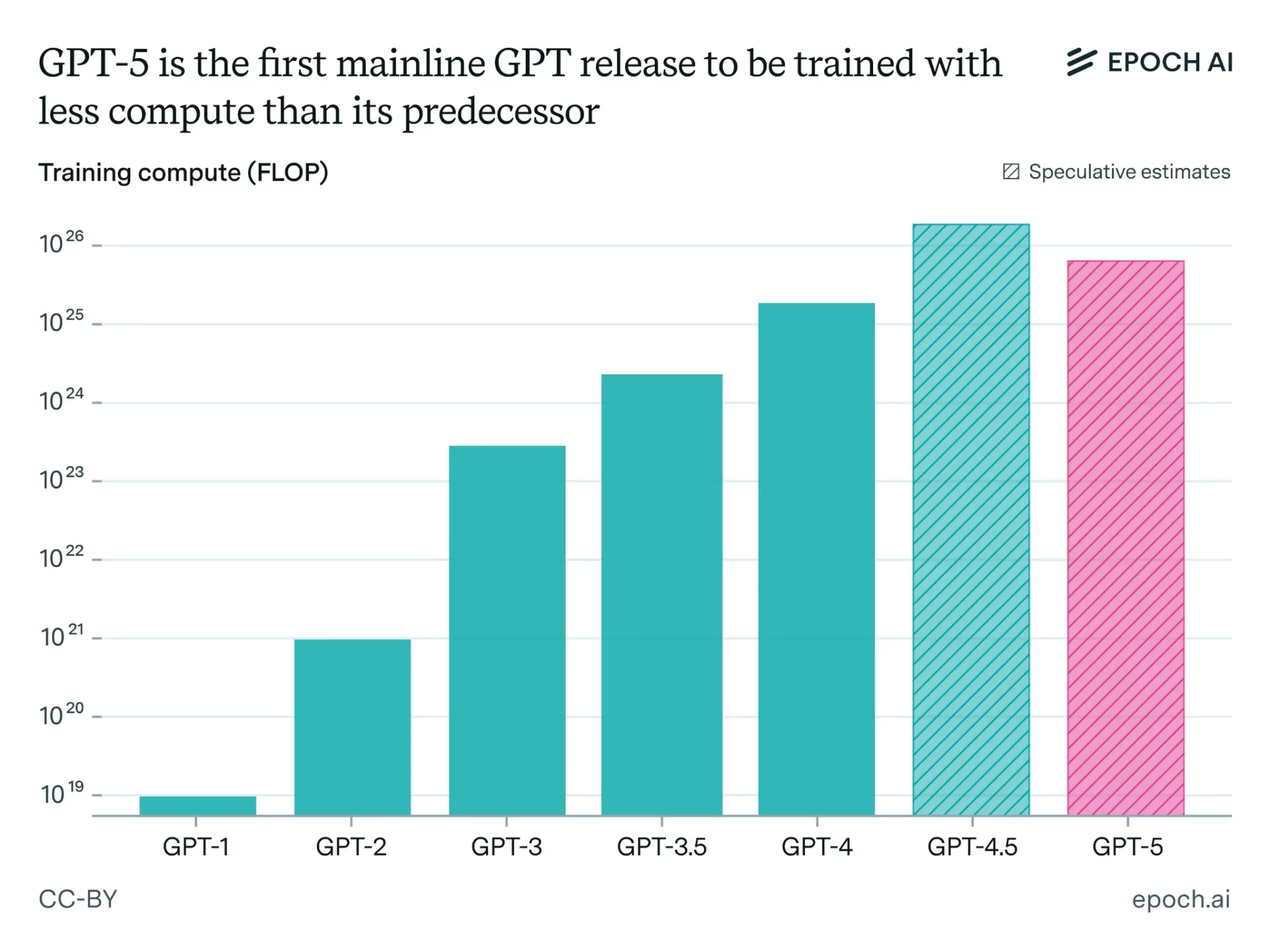
GPT-5は、前のバージョンよりも少ない計算量で訓練された初の主要なGPTモデルである
図:「Why GPT-5 used less training compute than GPT-4.5 (but GPT-6 probably won’t)」から
彼らの分析によるとGPT-5は事前学習と事後学習を合わせて5*10^25FLOPsの計算量でトレーニングされた可能性が高く、事後学習に至っては10^24FLOPs台の可能性もある。
一方で「AI 2027」で2025年にリリースされると予想されていたAgent-0モデルの計算量はおよそ10^27FLOPsで、20倍以上も異なる。
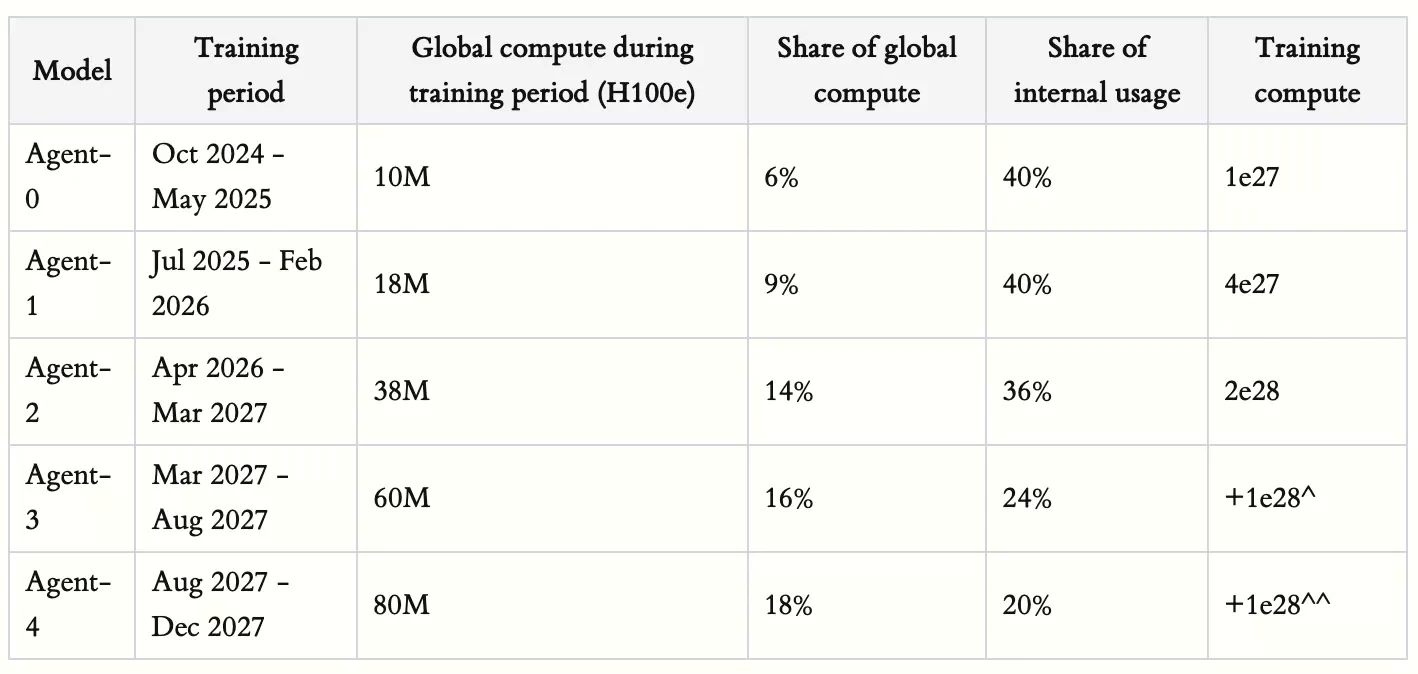
AI 2027のモデルに使用された学習計算量
図:「AI 2027 Compute Forecast」から
これらの分析を総合すると、当初は少なくとも10^27FLOPsの計算量でトレーニングされたモデルがGPT-5としてリリースされると予想されていたが、現実には10^25FLOPs台の計算量でトレーニングされたモデルがGPT-5としてリリースされたことになる。
GPT-5の性能が微妙にしか向上しなかったのは、開発時の学習計算量が頭打ちになったからではなく、そもそも学習計算をあまり行っていないということなのだろう。
つまり、今後学習計算量を増やせば、GPT-5の性能はまだまだ向上しうるということだ。
なぜOpenAIが学習計算量を増やさなかったのかには諸説あるが、EpochAIも分析しているように、最も有力なのは、LLMを強化学習で性能を向上させるパラダイムは始まったばかりであり、学習環境を整える試行錯誤や報酬ハッキングを防ぐ、AIの安全性を守る観点からの試みに重点を置いたため、当初の想定よりは遅れているという説である。
これは、学習計算量を増やすための準備期間が予定より長引いていることを意味すると思われる。
強化学習のパラダイムは始まったばかり
2024年9月にOpenAIがo1をリリースしてから推論モデルの時代が始まった。
GPT-1からGPT-4.5までは、より大きなモデルでより大きなデータを事前学習するパラダイムが主流だった。
しかし事前学習の計算量拡大も、主にテキストデータの枯渇(マルチモーダルデータに関しては余裕があるとされる)により、このままではいずれ学習計算に使うデータが不足すると数年前から予想されていた。
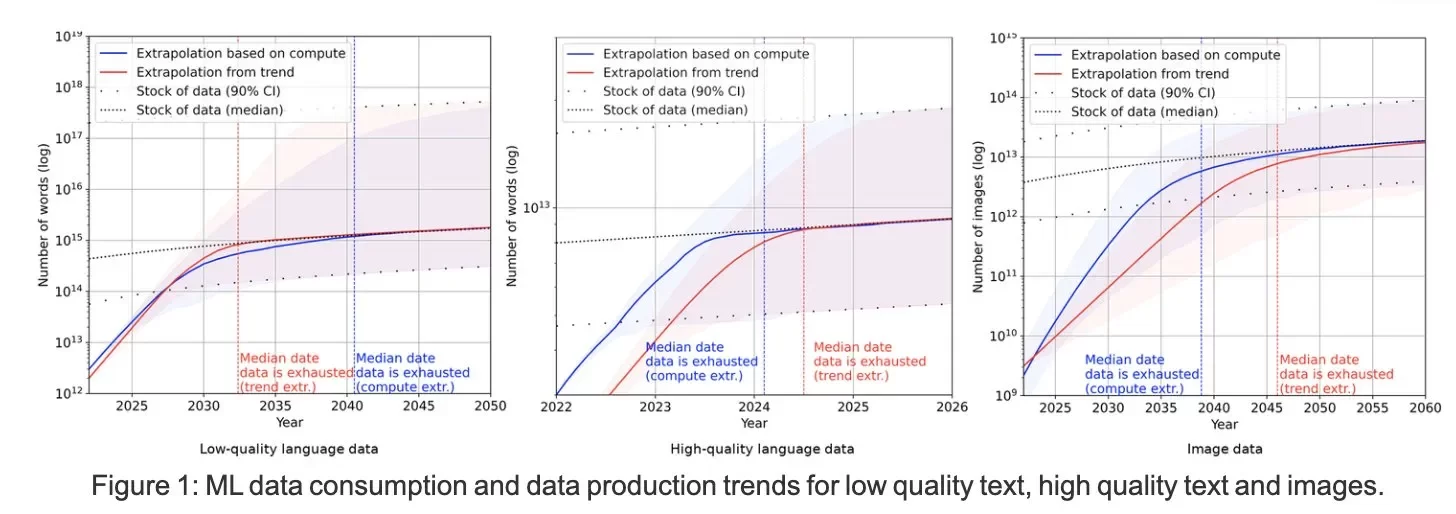
低品質のテキスト、高品質のテキスト、画像のMLデータ消費とデータ生成の傾向
図:「Will we run out of data? Limits of LLM scaling based on human-generated data」から
そこで学習計算量をさらに増やすために新たに出てきた手法が推論モデルのパラダイムであり、ある問題に対してより長く生成するトークンを費やし、何らかの正誤判定で報酬を与え強化学習を実行することで、よりモデルの性能を引き出すことが可能になった。事前学習したベースモデルを用いて強化学習を行うため、このフェーズを事後学習という。
この事後学習のパラダイムはまだ始まったばかりである。
まず、去年末のo1がおよそ10^23FLOPs台、o3が10^24FLOPs台、GPT-5が先ほども言ったように10^24~25FLOPs台の事後学習で訓練された可能性が高い。
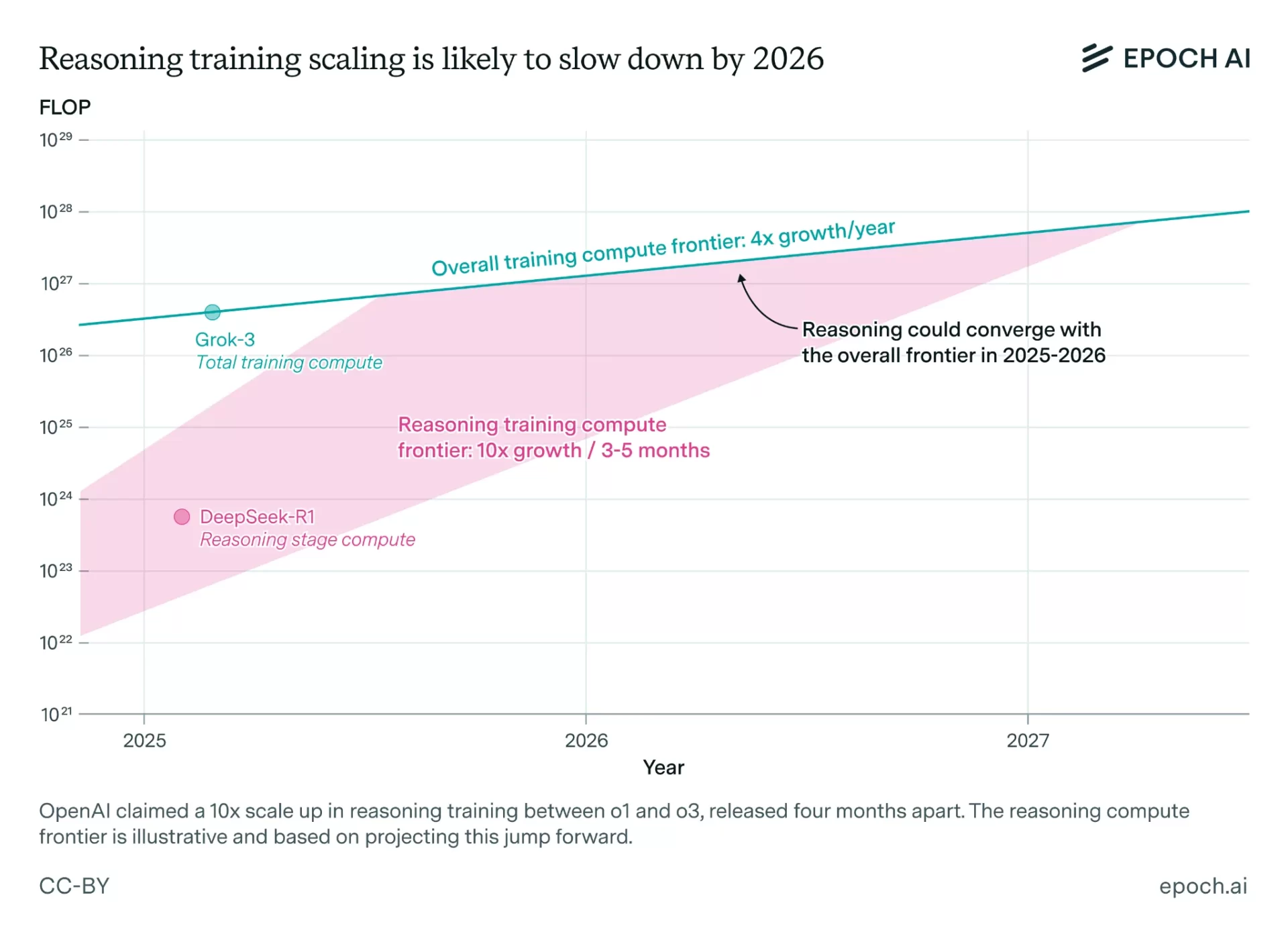
推論トレーニングの拡大は2026年までに鈍化する可能性が高い
図:「How far can reasoning models scale?」から
そして、事後学習に費やせるOpenAIのようなフロンティアAI研究機関の計算量は今年だけで2*10^27FLOPsあり、2027年末までに2*10^28FLOPsと考えられる。現在事後学習に2*10^25FLOPsしか費やされていないと仮定すると、今年だけで100倍、27年末までには1000倍まで学習計算量を増やす余地が残されているということになる。
2027年末までのAGIの可能性
o1からo3が10倍の計算量拡大だとすると、1000倍まで計算量を拡大すれば、単純計算でo6にまで至ることになる。またアーキテクチャも一年間で3倍改善されると仮定すると2027年末までには、更に10倍の計算量拡大と同等の効果が見込まれる。
2027年末までに実効的に1万倍まで計算量を拡大できる(oシリーズのナンバリングが1つ上がると10倍になると考えるとo1からo7までの変化と同様)ことになり、AGIが実現する可能性がある。
実際に、AnthropicやOpenAIのGreg Brockman氏は、数年以内に実質的にAGIと言えるようなAIシステムを開発すると豪語している。
AGIはLLMの延長で達成できる可能性
また、ここ最近LLM(Transformer型モデル)がソロモノフ帰納(SI)に漸近し得るとする理論研究が同時多発的に発表されており、学習計算量拡大競争の延長上にAGIの姿が見えつつあると指摘されている。
もし、質的に非連続的な革新がなくてもAGIを開発できるのであれば、どの程度量的に拡大すればAGIが開発できるのかを考える必要が出てくる。
OpenPhilanthrophyと呼ばれるアメリカの慈善団体は早期からAGIに相当するような革新的なAI(Transformative)が実現する時期を計算量の観点で予想してきた。大雑把に言えば、AIモデルの学習に費やす計算量を増やせば増やすほど、どこかで革新的なAIが実現する可能性が高いと考え、その妥当な上限として地球生命史を全て計算でシミュレーションするために必要な計算量を仮定する。
すると以下のポストでわかりやすく示されているように、現在GPT-5の計算量スケールで実現されたモデルではAGIというべき性能には到達していない。
図:Xの投稿から
一方で、EpochAIによれば、2030年まで時間スケールを伸ばせば、少なくとも2*10^29FLOPsの計算資源を使用できる可能性が高く、アーキテクチャの改善も2年分上乗せすれば、2030年までに100万倍まで計算量を増やせる可能性が高い。
上記xでのポストでも視覚的に理解できる通り、2030年までに投入される実効計算量と残りの進化的な計算量の上限までの残りの計算量を対数的なスケールで考えると、今後5年以内にAGIが実現する可能性も高いと考えられる。
2030年までAIの性能向上は続く可能性が高い
例え2027年または2030年末までに、文字通り人間の行う認知タスクのほとんど全てを実行可能なAIシステムが存在しなかったとしても、科学研究を含む多くの業務を相当程度支援可能なAIシステムが誕生している可能性は高い。
一方で、2030年以降になると一つのAIモデルのトレーニングに必要な費用が1兆ドルを超えて、アメリカのGWPの3~4%を占めるようになると、実際にAIが経済的に有用なことが示され続けない限り、学習計算量の増加が鈍化すると想定される。
いずれにしても、5年以内にAIの進歩が止まる可能性は低く、今後2030年までの目先のトレンドを見ればおおよそAIの性能は高まっていくし、2027年末までには大きな飛躍が見られる可能性が高いと考えられる。
そのため、AIの進歩を過小評価せず、様々なシナリオに我々は備えておく必要があるだろう。
もし本当にAGIが近いうちに実現すると、AIの性能が固定計算資源の元でも飛躍的に高まる「知能爆発」、数百年の技術進歩が10年程度で達成される「技術爆発」、カルダシェフスケール文明への数十年での飛躍といった短期間で産業や経済が急成長する「産業爆発」が起こる。
突如として人類史上でも最も大きいと言えるような変化が社会を覆うことになるため、軍拡競争の高まり、AIの制御の不可能性、悪用による甚大な被害、人類が徐々にAIに依存するリスクなどを、今から議論していかなければならないだろう。