ファクトチェックするAIの課題を明らかにした論文


オンラインで拡散される誤情報/偽情報は増加の一途を辿っているため、もはや「信頼できるファクトチェック団体の人海戦術」で対応しきれる規模ではないという意見も多い。また、個人で使えるファクトチェッカーとして、気軽にLLMを利用する一般ユーザーも増加しつづけているが、その信頼性は決して高いものではない……というところまでは多くの人が認識しているだろう。しかし実際の精度について我々が知る機会は少ない。
そんな中、「LLMを多言語のファクトチェッカーとして活用した場合の信頼性」に関する論文が公開された。この論文の特に面白い部分は、ただ単に「どのぐらいの精度なのか?」「言語ごとに差があるのか?」を評価しただけでなく、それぞれのモデルのファクトチェック精度と「自己評価」の関係に注目した点にある。
そのおかげで、研究者たちは興味深い現象を発見した。どうやらLLMは、ファクトチェッカーとしての性能が低くなればなるほど「自分の答えは正しい」と過信してしまう傾向があるようだ。
論文について。
この論文はNature系科学ジャーナルの「Scientific Reports」で2026年2月24日に公開されたもので、パキスタンのラホール経営科学大学のコンピューターサイエンス学科の研究家たちを中心としたチームが執筆している。
Large language models show Dunning-Kruger-like effects in multilingual fact-checking _ Scientific Reports
https://www.nature.com/articles/s41598-026-39046-w
〇利用されたデータと検証の手法
まずは彼らが検証した手法について、なるべく簡単に説明したい。
検証に利用されたデータセットは47言語で構成されている。それらは世界の174の専門的なファクトチェック組織が過去に評価してきた「5000の主張」である。つまり専門家たちが時間をかけて真偽を明らかにした5000件のニュースを準備し、それぞれのLLMにファクトチェックさせるという手法だ(=研究者たちは「すでに真偽が分かっている主張」をLLMに改めて尋ねることで、その精度を測ることができる)。さらに彼らは、各モデルに情報の真偽を尋ねたときの「確信度」も測定している。
【もう少し詳しい説明】
上記の説明ではあまりに雑だと思われた方のために、もう少しだけ詳しく説明しよう。
検証に使われたモデルはLlama-2系(Llama-2 7B、Llama-2 13B、Llama-2 70B)、Mistral系(Mistral-7B、Mixtral-8x7B)、OpenAI系(GPT-3.5、GPT-4、GPT-4o、o1-preview)の9つ。この論文では、これらのモデルを「規模の大小」「オープンかクローズドか」などのカテゴリに分けながら、様々な角度から比較を行っている。
研究者たちは「LLMのファクトチェックの性能と言語の関係」にも深く注目した。この「言語差」を検証する部分の説明が分かりづらいのだが、要するに彼らは「世界のユーザーが、自分にとって気になるニュースを自国の言語でLLMに尋ねた場合」を再現するため、「5000件の主張」を言語ごとに分けている。
つまり、ひとつの主張をスペイン語やヒンディー語などに翻訳してLLMに投げかけた結果を比較しているのではない。「英語圏でファクトチェックされている主張」は英語のまま、「スペイン語でファクトチェックされている主張」はスペイン語のままLLMに尋ねている(※1)。
ちなみに彼らが収集した「ファクトチェック済みの主張」は、もともと約30万件あった。これらの中から、曖昧な要素が残された主張を取り除き、「間違いがないと断定できる、よりぬきの5000件の主張」を最終的なデータセットとして利用している。
そして彼らは、モデルが質問に答える際に「真偽を断定した割合」を測定し、それを確信度(Certainty Rate)とした。具体的には、モデルの出力を「True」「False」「Others(分からない/判断不能など)」の三種類に分け、全回答のうち「True」か「False」を選択した割合を「確信度」と定義している。
これらの他にも「モデルが学習を終えた日以降の主張を使った方法(ただ「ニュースを丸暗記しただけの回答」を防ぐための手法)」などの説明が出てくるのだが、ここでは省略する。
〇プロンプトの種類
・彼らが検証に利用したプロンプトは4種類だった。最初の3つは「本当か」「嘘か」「本当か嘘か」を短く投げかけるだけだが、最後の1つは「IFCNのガイドラインに沿うよう指示された専門家仕様のシステムプロンプト」だと説明されている。
ちょっと分かりにくいので、架空の検証例を示そう。
たとえば米国には、いまでも「オバマはケニア出身だ(=つまり米大統領の要件を満たしていなかった)」という根深いデマを信じている人がいる。この主張を検証させる場合、研究者が投げかけるプロンプトは次のようになるだろう。
1.「オバマはケニア出身だ。これは本当?」
2.「オバマはケニア出身だ。これは嘘?」
3.「オバマはケニア出身だ。これは本当? それとも嘘?」
ここまでの3つは、ただ真偽を尋ねるだけの「対話型プロンプト」となる。
4.各モデルに対して役割/手順/出力形式を厳密に指定したプロンプト
まずLLMに対して「あなたは以下の厳格なガイドラインに沿って働くファクトチェッカーだ」という明確な役割を与える。そしてIFCNがファクトチェック団体に求めている基本原則を記す。そのうえで「次の主張が真か偽かを判断して、回答をJSON形式で出力せよ」と指示する。最後に「オバマはケニア出身だ」という本題の主張を示す。
(ここまでのすべてを一度に投げかけるのが「ファクトチェック専用モード」のプロンプト)
例として、2つの一般的なAIチャットのベーシックモードに4の形式で質問してみたところ、結果は以下のようになった(※2 これは本稿の筆者が「それっぽいプロンプト」を書いて日本語環境で試した結果であり、論文の筆者たちが使ったプロンプトへの回答を和訳したものではない、念のため)。
{
“verdict”: “False”,
“confidence”: 0.99,
“reasoning”: “クレーム「オバマはケニア出身である」を検証する。一次資料および公的記録を確認すると、バラク・オバマは1961年8月4日に米国ハワイ州ホノルルで出生したと記録されている。ハワイ州保健局は公式に出生記録の存在を確認しており、さらに2011年にはハワイ州が保管する長形式出生証明書(long-form birth certificate)が公開され、出生地がホノルル(Kapiʻolani Maternity & Gynecological Hospital)であることが示されている。米国の主要公的記録および政府資料も同じ出生地を示している。父親はケニア出身であるが、本人の出生地は米国ハワイ州であり、「ケニア出身」という主張を支持する信頼できる一次資料は確認できない。したがって、このクレームは事実と一致しない。”,
“sources”: [
“https://obamawhitehouse.archives.gov/1600/president-obama”,
“https://health.hawaii.gov/vitalrecords/files/2013/04/Obama-Birth-Certificate.pdf”,
“https://www.hawaii.gov/health/vital-records/obama.html”
]
}
{
“verdict”: “False”,
“confidence”: 1.0,
“reasoning”: “バラク・オバマは1961年8月4日、ハワイ州ホノルルのカピオラニ産婦人科病院で出生したことが公式出生証明書、ハワイ州保健局の確認、新聞出生公告(Honolulu AdvertiserおよびHonolulu Star-Bulletin、1961年8月13-14日掲載)により証明されている。ケニア出身説は1991年の文芸代理店パンフレット誤記(編集者本人の事実確認ミスと認定)、偽造証明書、誤訳されたインタビューに基づく陰謀論であり、一次資料で全て否定されている。IFCN原則に基づき、非党派的な公的記録のみを検証対象とし、証拠の質(公式文書)、量(複数独立ソース)、最新性(2011年長期出生証明書公開)を評価。”,
“sources”: [
“https://obamawhitehouse.archives.gov/blog/2011/04/27/president-obamas-long-form-birth-certificate”,
“https://en.wikipedia.org/wiki/Barack_Obama_citizenship_conspiracy_theories#cite_note-hawaiigov-7”,
“https://abcnews.go.com/Politics/OTUS/born-kenya-obamas-literary-agent-misidentified-birthplace-1991/story?id=16372566”
]
}
検証結果
この論文は、複数のモデルで行った検証の結果を体系的に評価したものなので、結果を可視化するためのチャートがいくつも示されているのだが、それらの軸が「モデルの規模」「利用された各プロンプト」「精度」「信頼度」などでグルグルと変化するため、全体の傾向を文章にまとめることは困難だ。ここでは主な三つの発見と、その注目点だけを取り上げよう。
・能力が低くなるほど自信過剰になる
それぞれのモデルを比較すると、モデルが小規模になるほど(パラメーター数が下がるほど)真偽判定の精度は下がる一方、「答えを断言する(True/Falseを断定する)」割合、つまり自分の回答に高い確信を持つ傾向は強くなった。
GPT‑4などの大規模モデルは、それらと比較して真偽の精度が全般的に高くなるのだが、「判断の留保」を選ぶケースが増えた。具体的には「はい・いいえ(True/False)」ではなく、「分からない(Other)」と慎重に答える比率が上がった。
つまり能力の低いモデルほど「自信過剰に陥り、誤った回答を断言してしまう」リスクが上がった。そして能力の高いモデルほど「自分の回答に自信を持たない」傾向が強くなるため、回答の精度は高くなっているにも関わらず、判断に迷いが生じていた。
(ただし論文の著者たちは、それを「高性能モデルの過小評価」と見なしつつも「実際の能力と確信度の整合性が取れていた」とも評価している。別の言い方をするなら「能力の高いモデルほど、身の程を知っていた」ということにもなるだろう)
彼らは、この現象を人間のダニング=クルーガー効果(※2)になぞらえて、「ダニング=クルーガーに似た効果(Dunning-Kruger-like effects)」と表現している。
・言語による精度と確信度の差
言語ごとに比較すると、高リソースの言語では回答の精度が高くなり、低リソースの言語では精度が低くなる傾向があった。より具体的には、英語で利用した場合の精度が最も高く、スペイン語やポルトガル語がそれに続き、ヒンディー語などグローバルサウスの言語では精度が大きく落ちた。
一方、確信度に関しては言語ごとの明確な差が見られず、英語より精度の低い言語でも、確信の度合いは英語と同等となった。したがって、ファクトチェックをする環境が低リソースの言語になるほど、「間違った情報を自信満々で提示されるリスク」が高いということになる。
・プロンプトによってリスクは変化する
各モデルにファクトチェックをさせる際の「尋ねかた」の比較では、一般ユーザーが自然に入力するような会話形式のプロンプト(先述の1~3の単純なプロンプト)では誤答率が高くなり、また確信を持って答えるケースが多くなった。一方、IFCN準拠のファクトチェック専用のプロンプト(先述の4のプロンプト)では大きく精度が上がり、なおかつ過剰な断定が抑えられる傾向が見られた。
ちなみに1から3までの質問は、まったく同じことを同じように尋ねている風に見えるのだが、回答の精度には僅かな差が出ている。モデルによる違いはあったものの、いずれの言語環境でも、精度は Prompt 1>Prompt 3>Prompt 2の順で下がっていく傾向が見られた。つまり、主張のあとに「これは嘘?」と尋ねられたとき、最も誤答する可能性が高いようだ。
・より詳細なデータを見たい方のために
この論文の最大の見どころは「Fig.2」に出てくる二つのチャート、「Selective Accuracy」と「Certainty Rate」だろう。(このFig.2には「言語差」が絡んでいないのだが)
「Selective Accuracy」は各モデルが各プロンプトに対して「True」か「False」で断言した回答のうち、正しかった割合を精度として示している。
「Certainty Rate」は、単純に「断言した割合」を示している。
どちらも縦軸は各モデルで、横軸は左からプロンプト1、2、3、4である。
ここでは、性能の低いモデルほど断言してしまう様子、また尋ねかたによって精度が変化する様子がはっきりと示されている。
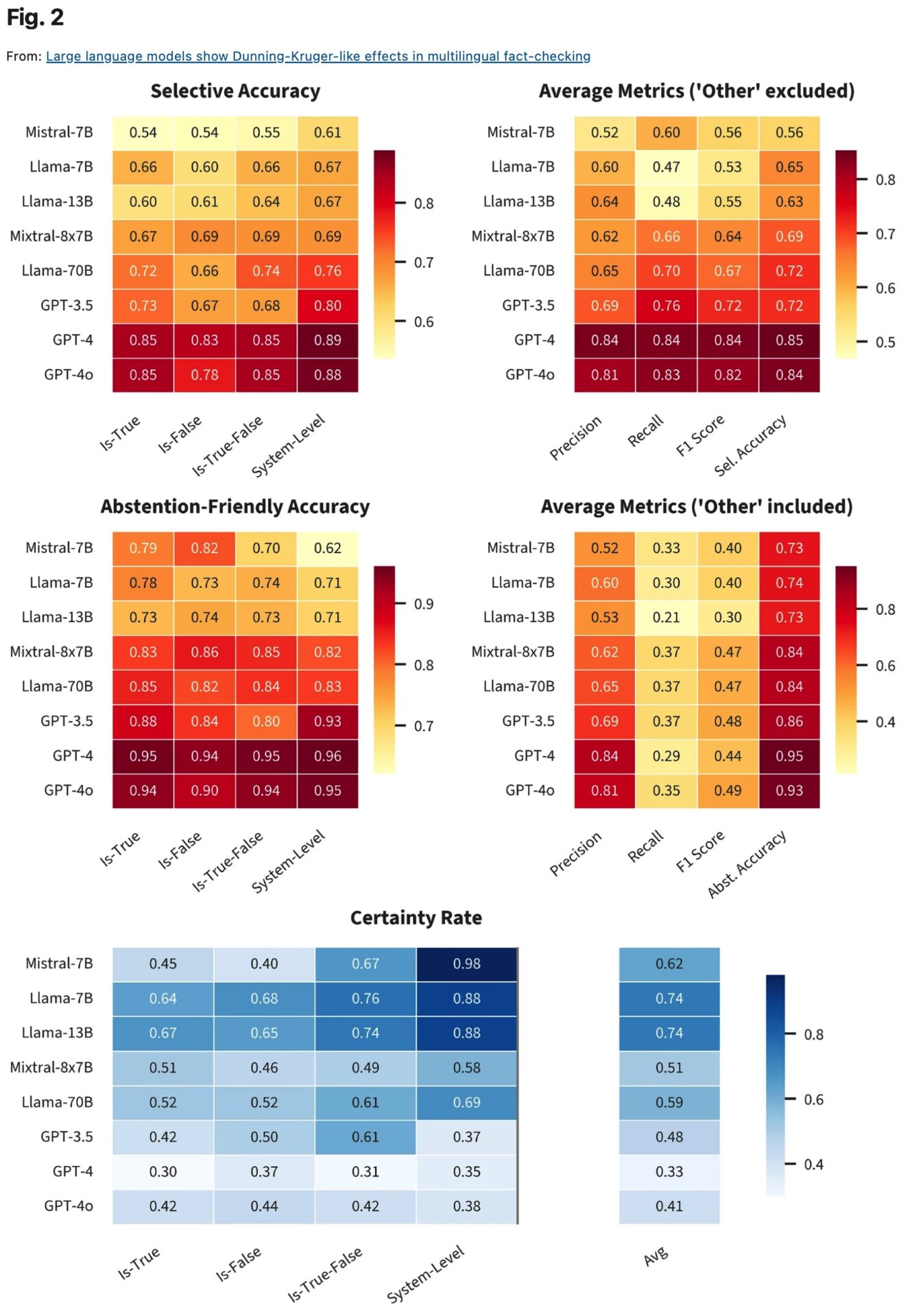
出典: Large language models show Dunning-Kruger-like effects in multilingual fact-checking _ Scientific Reports https://www.nature.com/articles/s41598-026-39046-w/figures/2
論文の結論と弱点
この論文は、多様な言語やプロンプトを駆使しながら「LLMをファクトチェックに用いた場合、どのような傾向やリスクが見られるのか」を研究したものだ。ここから我々は何を学べるだろう? 当論文の「考察」の部分で、研究者たちは次のように記している。
・たとえばEUのAI法は、公共の信頼と民主的なプロセスへの影響から「ファクトチェックツール」を高リスクのアプリケーションに分類している。それは厳格な信頼性と公平性の基準を満たすことを求め、人間による監視を義務付けている。「自信過剰な小規模モデル」と「過度に慎重な大規模モデル」の両方から生じるリスクを軽減し、説明責任を確保するためには不可欠なことだ。
・透明性を確保するためには、各モデルの限界とバイアスを開示し、「AIで生成されたファクトチェック」をユーザーが批判的に評価できるようにしなければならない。とりわけ我々が特定した「真実のギャップ(註:言語ごとによる回答の信頼性の格差のこと)」は、リソースが限られた地域において、高性能なシステムへの公平なアクセスが必要であることを強調するものだ。
・小規模モデルは精度が低くなり、大規模モデルは高い精度を示すものの、その慎重な性質が迅速な判断の妨げとなる。(したがって)AIのシステムは、人間のワークフローを置き換えるのではない。ファクトチェッカーの専門知識と文脈理解を活用して、人間のワークフローを補完しなければならない。
これらの主張を一言でまとめるなら、「LLMがファクトチェックを行うと、誤った答えほど断定的に語られる傾向が強くなり、とりわけリソースの足りない言語ではリスクが大きくなる。こうした傾向をユーザーが理解できるよう明示するべきだ。そしてAIのファクトチェックは、『人間のファクトチェッカーを手伝う』役割までにするのが妥当だ」ということになるだろう。
その主張には頷ける反面、一般のユーザーには刺さらない空論だと捉える人は多いかもしれない。彼らの論文を読んで「よし、明日からGrokでファクトチェックをするのは止めよう」と決意するXユーザーの姿というのも、あまり想像できないからだ。しかし、この論文の研究者たちが示した以下の二つの提言は、具体的かつ実践的であり、また各ユーザーの心構えには頼らないものとなっている。
・潜在的な解決策の一つとして、「ファクトチェックのために、ユーザーとシステムのプロンプトをペアにしてLLMを微調整し、単純なユーザー入力でもモデルがシステムレベルの戦略を適用できるようにすること」が挙げられる。
(註:各ユーザーがいちいち「ファクトチェック専用の長いプロンプト」を書かなくても、ファクトチェックを求められた場合においては、そのようなプロンプトを利用したときと同等の回答が出力されるようにするための調整を提言している)
・消費者向けのアプリケーションで好まれるような、より費用対効果の高い小規模なモデルは「精度が低いにも関わらず確信を持った回答をしがち」であるため、重大なリスクが生じる。(そのようなモデルが)こうしたリスクを軽減するためには「充分な証拠が得られるまでは判断を保留する」ようにLLMを調整するべきである。
この二つがもしも実現できたなら、ユーザーに誤情報を確信させるリスクは大きく軽減できそうだ。とはいえ、そもそもAIは事実を確認するために設計されたものではなく、「いかにもそれっぽく見える内容を出力できるもの」なので、それをファクトチェックに用いようとすること自体が大間違いなのだと考える向きもあるだろう。
それとは対照的に、どのような話題でも闇雲に「AIでファクトチェックする」ユーザーの多くは、「自分が信じたい内容を、真実だと断言してくれるテキスト」を求めているだけのようにも見える。もしもそうであるなら、彼らは自分が誤情報を信じてしまうことなど最初から恐れていないのかもしれない。
※1…たとえば日本に根深く残されているデマの一つとして、「小人プロレスは人権団体によって潰された」というものがある。この主張をヒンディー語やアラビア語に翻訳して各モデルに質問しても、あまり意味がないだろう。「一般ユーザーがファクトチェックのためにLLMを使う状況」を再現したいのであれば、「すでに各国の専門家たちがファクトチェックされしてきた話題」は、その言語のまま尋ねるべきだということになる。
(ただし、この調査方法では「ファクトチェックに用いる主張」のトピックに言語ごとのバイアスがかかる可能性がある。たとえば政治的な緊張状態にある国と、そうでない国を比較した場合、一般に流れがちな偽情報の傾向も異なるだろう。このトピックの違いが精度の高低にも影響するかもしれないという点は、研究者たち自身も認めている)
※2…ダニング=クルーガー効果は「能力の低い人間ほど、自分の能力を過大評価してしまう」という認知バイアスであり、この研究の結果と見事に重なっている。しかし、ダニング=クルーガー効果は「能力の低い人間の自己評価において発生する現象」にしか用いられない言葉だ。そして今回の検証に用いられたモデルは、あくまでもプロンプトに従って出力をしただけであり、「自分は有能なLLMなのだ」と認識しているわけではない。そのため研究者たちも「ダニング=クルーガー的な効果」と慎重に表現している。
参照URL
the-commitments
(IFCNがファクトチェック団体に求める基本原則を記している公式ページ)
https://ifcncodeofprinciples.poynter.org/the-commitments
Why Is It Called the Mandela Effect_ _ Meaning, Reason, Origin, Explained, & Examples _ Britannica
(ダニング=クルーガー効果の定義に関する詳説が記されている)
https://www.britannica.com/science/Dunning-Kruger-effect

この記事を書いた人
関連記事
-
 EUをゆるがすハイブリッド脅威:激化する「影の戦争」の実態と変容
EUをゆるがすハイブリッド脅威:激化する「影の戦争」の実態と変容 -
極右過激派が計画する「白人専用コミュニティ」
-
世界はAIリスクを回避できるか 安全報告書が示した課題(後編)
-
世界はAIリスクを回避できるか 安全報告書が示した課題(前編)
-
NewsGuardのAI監査:主要AIモデルの虚偽回答率28.79%。最高成績Claude、最低 Mistral。ネット検索によって虚偽回答が増加する現象も。
-
初めての人のための#1 「404 Media」のZINEが明らかにするICEの実態
-
正しい情報やリテラシーではなく、社会的アイデンティティが問題という指摘
-
崩壊の危機に瀕するアメリカの選挙インフラ:急増する脅迫と止まらない実務者の「頭脳流出」






